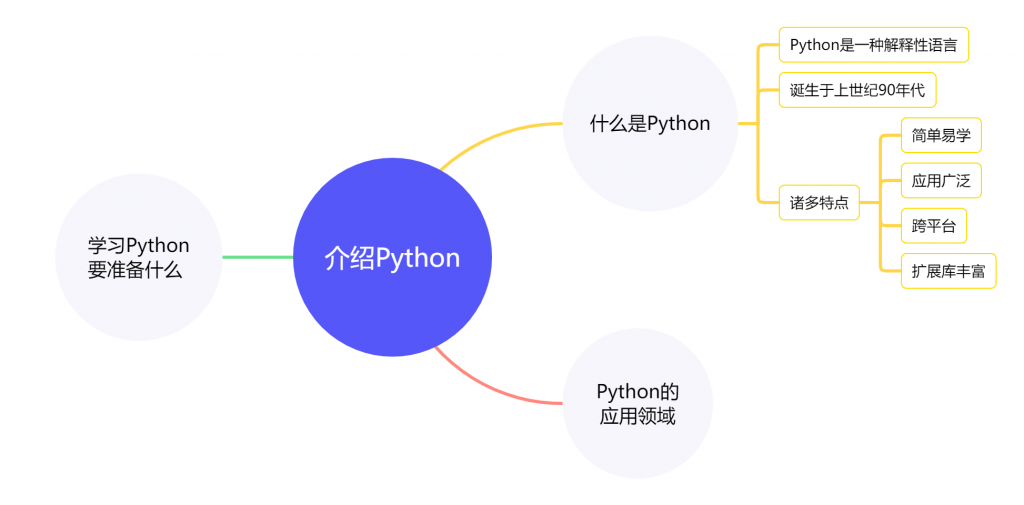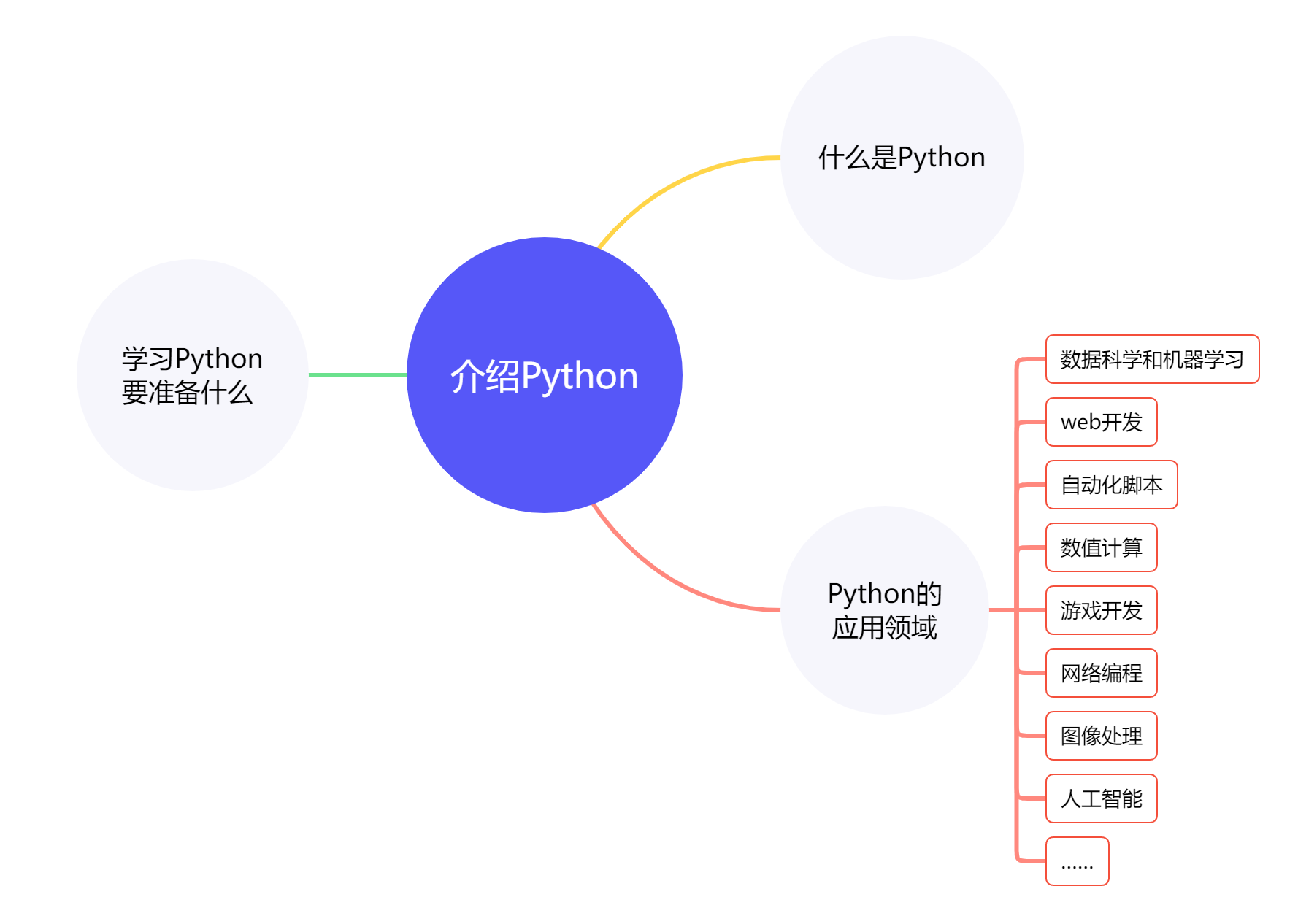
上一讲我们说了Python的诸多特点,围绕着Python的这些特点,使Python几乎可以在各行各业中发挥出它的特点。
例如,在科学计算领域,Python常常被用来进行数据分析、机器学习和人工智能等任务。NumPy和SciPy等库可以帮助程序员进行数值计算和科学计算。
在人工智能领域,Python也是一种流行的语言,因为它有着许多强大的库,如TensorFlow和PyTorch,可以用于深度学习和神经网络等任务。
Python也可以用于开发Web应用程序。Django和Flask等Web框架使得使用Python进行Web开发变得容易。这些框架提供了许多有用的工具和库,可以帮助程序员快速开发高质量的Web应用程序。因此,Python还可以用于Web开发。
Python也被广泛地应用于图像处理和游戏开发领域,例如pygame库可以搭建基础的游戏框架,而OpenCV库则可以实现计算机视觉的许多应用,包括人脸识别、运动跟踪和实时视频分析等。
如今,几乎在各行各业,都可以看到Python的身影,因为其庞大的库函数,使得越来越多的人开始用Python辅助自己的工作及学习,这也是我们之所以选用Python作为初学者学习的语言的一个原因。
那么,在开始学习Python之前,需要做哪些准备工作呢?下一讲我们就详细来进行一下说明。