为了督促自己不停下学习的脚步,我决定尽可能每天来这里更新自己在编程方面学习和研究的成果,只要平时闲暇之余有所感触,我都会发到这里,大家一起勉励。
首先是上周在QQ群里和大家提到了制作“成语接龙”游戏的话题,在聊起这个话题之后,很多朋友给出了响应,并纷纷制作出了自己的项目,在这里首先感谢大家的支持。
这里稍稍总结一下。
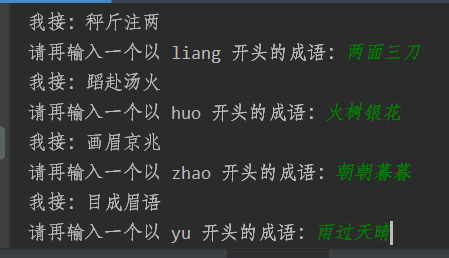
游戏的规则我想我们大家都是了解的,无非就是在说出一个成语为前提的情况下,第一个字要和上一个人的答案中最后一个字相同,或同音同字,或同音不同字,或同字不同音。一开始,大家主要以制作同音同字这种情况为主,遇到的问题瓶颈在于,结尾的字太多了,相当于要把所有汉字开头的成语全部罗列出来,这将带来一个庞大的数据集合(列表),在Scratch群中,大家借助了列表的文本导入功能,成功将这个问题进行了变相的解决,之后按照读音,对文字进行分类,每个音一个列表,进而实现了同音不同字的解决方案。而对于最后一个同字不同音的部分,虽然可行,但奈何要从庞大的列表数据中筛选这些内容确实效率不高,所以最终没有特别的去实现它。
在Python群中,讨论的方向则在一开始就有了分歧,一部分学员依靠数据本地化,采用了类似Scratch中把成语存储在本地数据中的方法,建立了一个庞大的库文件(-_-||),另一部分学员则准备使用网络爬虫功能实现网络数据的采集,让网络作为程序天然的数据库存在,最终的事实证明这样的方案也确实优秀。
我们找到了一个网站,这个网站使用拼音作为页面,页面中列出了该读音下所有成语,这样问题转化为两个:1、将上一条成语的末尾文字的拼音找出来;2、从对应的成语列表页面内搜集所有的成语,并随机取出一个。
第1个问题,我们直接发现就在这个网站里,支持对每个文字进行Unicode检索,检索结果中恰好就有该文字的拼音,而且是所有读音,于是这个问题又分解成了两个新的问题:1、将该文字转换为Unicode;2、从文字检索结果页面中搜集所有的读音,并随机取出一个。
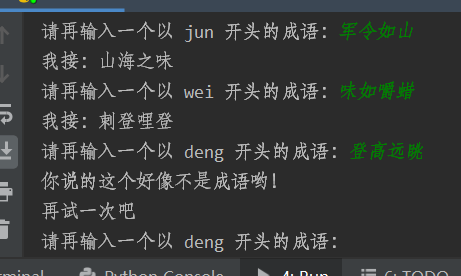
现在问题成了三个,但三个问题的难度对于爬虫知识来说,都不算难,其中页面数据搜集部分涉及到了正则表达式知识。这些问题多多少少都给大家带来了一些问题,绝大部分使用爬虫来做的学员只能使用比较繁琐的字符串处理方法,在获取的页面内容中搜集结果,正则表达式部分由于没有接触过,都不太明白该如何下手。最后在大家一起讨论+学习的氛围下,我们成功完成了正则表达式的匹配,也成功搜集到了我们要搜集的内容,并最终实现了在线版的“成语接龙”游戏。
之后我又在基础上,实现了判断回答的词组是否为成语等等。
然后,我通过玩这个游戏,认识了好多从来没听过的成语……